Một câu nói nổi tiếng của William Glasser, chuyên gia tâm thân học Mỹ:
Chúng ta học….
10% của những gì ta đọc được
20% của những gì ta nghe thấy
30% của những gì ta nhìn thấy
50% của những gì ta nghe và nhìn thấy
70% của những gì ta thảo luận
80% của những gì ta trải nghiệm
95% của những điều ta dạy người khác

Xem thêm: Phần mềm hiện thị dữ liệu, phân tích dữ liệu
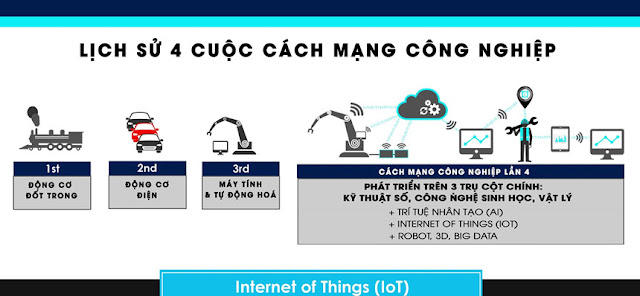
Theo một báo cáo mới được công bố tại Diễn đàn Kinh tế Thế giới, những thay đổi về nhân khẩu học và tiến bộ kỹ thuật có thể dẫn đến việc 5 triệu việc làm sẽ biến mất vào năm 2020. Tuy nhiên, ngược lại có một số công việc lại được dự đoán sẽ có sự tăng trưởng đáng kể, trong đó có nghề phân tích dữ liệu.

Xem thêm: Chọn nghề phân tích dữ liệu?



 đem lại cho ngành du lịch khách sạn")



 CHATBOT LÀ GÌ?")


 (PHẦN 1)")

")






: LỢI ÍCH CỦA CHATBOT")




 (PHẦN 2)")
 REGRESSION TREE VÀ DECISION RULES")
")







 GIẢI PHÁP KHAI THÁC CUSTOMER DATA HIỆU QUẢ")

: ƯU & KHUYẾT ĐIỂM, STOPPING & PRUNING METHOD")




")



")









