
Hacker tối qua đã tung thông tin nghi là của hai triệu khách hàng từ một ngân hàng Việt Nam lên Raidforums, một website chuyên mua bán dữ liệu.
Các thông tin bị rò rỉ bao gồm tên đầy đủ, số chứng minh thư, số điện thoại, địa chỉ nhà, ngày tháng năm sinh, giới tính, email và nghề nghiệp.

: KHAI PHÁ DỮ LIỆU LÀ GÌ?")
 (PHẦN 2)")
 mang lại trong ngành du lịch")









 (PHẦN 1)")
")


 (PHẦN 2)")
")



: LỢI ÍCH CỦA CHATBOT")
 REGRESSION TREE VÀ DECISION RULES")




")

 : CLASSIFICATION & REGRESSION TREE (CART)")

")

: ƯU & KHUYẾT ĐIỂM, STOPPING & PRUNING METHOD")
")


 (PHẦN 1)")



: C4.5 (ENTROPY)")

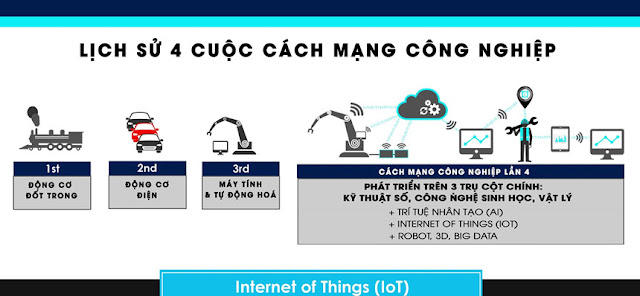


 – DỮ LIỆU KHÁCH HÀNG LÀ GÌ?")









