
Ngăn ngừa lãng phí bộ nhớ trong Java Collections như thế nào?
JDK collections là thư viện implement chuẩn của lists and maps. Nếu bạn nhìn vào snapshot bộ nhớ của một ứng dụng Java lớn điển hình, bạn sẽ thấy hàng nghìn hoặc thậm chí hàng triệu instances của java.util.ArrayList, java.util.HashMap, …

Collections không thể thiếu để lưu trữ và thao tác dữ liệu trong bộ nhớ. Nhưng bạn đã bao giờ xem xét liệu tất cả collections trong ứng dụng của bạn có sử dụng bộ nhớ tối ưu không? Nói cách khác, nếu ứng dụng Java của bạn bị lỗi OutOfMemoryError huyền thoại hoặc bạn từng gặp problem với GC pause thật lâu – bạn đã kiểm tra xem phần source code với collections của bạn lãng phí memory nhiều như thế nào chưa? Nếu câu trả lời của bạn là “không” hoặc “không chắc chắn”, thì hãy đọc tiếp.
Đầu tiên, lưu ý rằng JDK collections, bản chất bên trong của nó đã có gì thần bí cả. Chúng được viết bằng Java. Source của họ đi kèm với JDK, vì vậy bạn có thể mở nó trong IDE của bạn. Nó cũng có thể dễ dàng tìm thấy trên web. Và, khi nó được phơi bày ra, hầu hết collections không phải quá tinh vi khi nói đến tối ưu hóa bộ nhớ.
Hãy xem xét, ví dụ, một trong những class collections đơn giản và phổ biến nhất: java.util.ArrayList.Bên trong mỗi ArrayList căn bản là một mảng elementData Object []. Đó là nơi các phần tử của list được lưu trữ. Hãy xem cách mảng này được quản lý như thế nào.
Khi bạn tạo một ArrayList với hàm tạo mặc định, tức là gọi ra new ArrayList() , elementData được thiết lập để trỏ đến một mảng có kích thước bằng 0 và singleton (elementData cũng có thể được thiết lập là null). Khi bạn thêm phần tử đầu tiên vào danh sách, phần tử thật nha (non null), elementDatađược tạo và đối tượng được cung cấp sẽ được chèn vào nó. Để tránh thay đổi kích cỡ mảng mỗi lần thêm phần tử mới, nó được tạo với độ dài 10 (mặc định). Chú ý chỗ này: nếu bạn không bao giờ thêm nhiều phần tử vào ArrayList này, 9 trong số 10 vị trí trong mảng elementData sẽ vẫn trống. Và ngay cả khi bạn xóa danh sách này sau, elementData vẫn sẽ không thu nhỏ. Sơ đồ dưới đây tóm tắt vòng đời này: 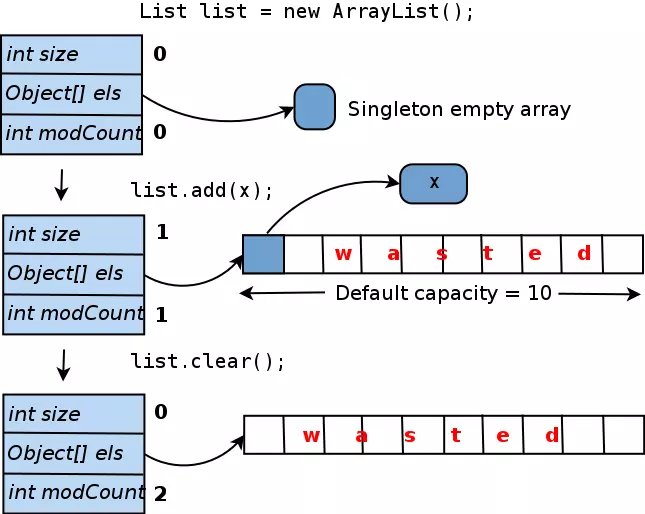
Bao nhiêu bộ nhớ bị lãng phí ở đây? Trong điều khoản tuyệt đối, nó được tính như (kích thước con trỏ đối tượng) * 9. Nếu bạn sử dụng HotSpot JVM (đi kèm với Oracle JDK), kích thước con trỏ phụ thuộc vào kích thước heap tối đa. Thông thường, nếu bạn chỉ định -Xmx nhỏ hơn 32 GBs, kích thước con trỏ là 4 bytes; cho heap thì lớn hơn hơn, đó là 8 bytes. Vì vậy, một ArrayList được khởi tạo với hàm tạo mặc định, và chỉ với một phần tử được thêm vào, lãng phí ở đây là 36 hoặc 72 bytes.
Trong thực tế, một empty ArrayList cũng lãng phí bộ nhớ, bởi vì nó không mang bất kỳ khối lượng công việc nào, nhưng một đối tượng ArrayList, chính bản thân nó đã là non-zero và lớn hơn những gì bạn đang nghĩ. Đó là bởi vì, một điều, mọi đối tượng do JVM HotSpot quản lý đều có header là 12 hoặc 16 bytes, được JVM sử dụng cho các mục đích nội bộ. Tiếp theo, hầu hết các đối tượng collections chứa trường size, một con trỏ tới mảng nội bộ hoặc đối tượng “workload carrier” khác, một trường modCount được tạo ra để theo dõi các sửa đổi nội dung, v.v. Như vậy, ngay cả đối tượng nhỏ nhất có thể đại diện cho một empty collections có thể sẽ cần ít nhất 32 bytes bộ nhớ. Một số khác như ConcurrentHashMap sẽ còn mất nhiều hơn nữa.
Hãy xem xét một lớp sưu tập phổ biến khác: java.util.HashMap. Vòng đời của nó tương tự như của ArrayList và được tóm tắt dưới đây: 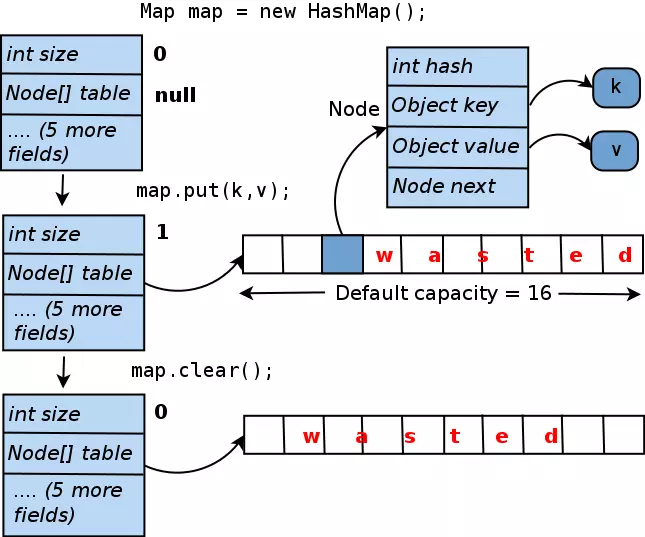
Như bạn có thể thấy, HashMap chỉ chứa một cặp khóa-giá trị lãng phí 15 vùng mảng nội bộ, có thể chuyển thành 60 hoặc 120 bytes. Những con số này là nhỏ, nhưng điều quan trọng là bộ nhớ bị mất bao nhiêu trong tất cả các collections của ứng dụng của bạn. Và nó chỉ ra rằng một số ứng dụng có thể lãng phí rất nhiều theo cách này. Ví dụ, một số component của Hadoop mà tác giả đã đích thân phân tích, mất mát bộ nhớ là khoảng 20% heap memory của chúng ta trong một số trường hợp! Đối với các sản phẩm được phát triển bởi các kỹ sư ít kinh nghiệm và không thường xuyên được xem xét kỹ lưỡng về performance, lãng phí bộ nhớ có thể còn cao hơn nữa. Có đủ trường hợp sử dụng, ví dụ, 90% các node trong một trêe khổng lồ chỉ chứa một hoặc hai children (hoặc không có gì cả), và các tình huống khác nơi mà heap có rất nhiều collections 0, 1 hoặc 2 phần tử.
Nếu bạn phát hiện các collections chưa sử dụng hoặc chưa được sử dụng trong ứng dụng của mình, cách bạn khắc phục chúng? Dưới đây là một số công thức phổ biến. Ở đây, collections có vấn đề của chúng tôi được giả định là một ArrayList được tham chiếu bởi data field * Foo.list*.
Nếu hầu hết các instances của list không bao giờ được sử dụng, hãy xem xét lazy init nó. Vì vậy, source code trước đây trông giống như …
|
1
2
3
4
5
|
void addToList ( Object x ) {
list . add ( x ) ;
}
|
…nên được refactor thành như sau
|
1
2
3
4
5
6
7
8
9
10
11
|
void addToList ( Object x ) {
getOrCreateList ( ) . add ( x ) ;
}
private list getOrCreateList ( ) {
// To conserve memory, we don't create the list until the first use
if ( list == null ) list = new ArrayList ( ) ;
return list ;
} < code class = "language-none" >
|
Hãy nhớ rằng lazy init không phải lúc nào cũng dùng được. Ví dụ, nếu bạn duy trì một ConcurrentHashMap có thể được cập nhật bởi nhiều thread đồng thời, source code lazy init không nên cho phép hai thread tạo hai bản sao của map này một cách vô tình:
|
1
2
3
4
5
6
7
8
9
10
11
|
private Map getOrCreateMap ( ) {
if ( map == null ) {
// Make sure we aren't outpaced by another thread
synchronized ( this ) {
if ( map == null ) map = new ConcurrentHashMap ( ) ;
}
}
return map ;
}
|
Nếu hầu hết các bản sao của list hoặc map của bạn chỉ chứa một số ít phần tử, hãy xem xét khởi tạo chúng với size ban đầu phù hợp hơn, ví dụ:
|
1
2
3
|
list = new ArrayList ( 4 ) ; // Internal array will start with length 4
|
Nếu collections của bạn là empty hoặc chỉ chứa 1 phần tử (hoặc cặp khóa-giá trị) trong hầu hết các trường hợp, bạn có thể xem xét một hình thức tối ưu hóa cực đoan. Nó chỉ hoạt động nếu collections được quản lý hoàn toàn trong class đã cho, tức là không thể truy cập trực tiếp vào collections đó. Ý tưởng là bạn thay đổi data type của mình, ví dụ. List to Object, để bây giờ nó có thể trỏ đến một danh sách thực, hoặc trực tiếp đến phần tử danh sách duy nhất. Phát thảo ý tưởng như bên dưới:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// *** Old code ***
private List < Foo > list = new ArrayList <> ( ) ;
void addToList ( Foo foo ) { list . add ( foo ) ; }
// *** New code ***
// If list is empty, this is null. If list contains only one element,
// this points directly to that element. Otherwise, it points to a
// real ArrayList object.
private Object listOrSingleEl ;
void addToList ( Foo foo ) {
if ( listOrSingleEl == null ) { // Empty list
listOrSingleEl = foo ;
} else if ( listOrSingleEl instanceof Foo ) { // Single-element
Foo firstEl = ( Foo ) listOrSingleEl ;
ArrayList < Foo > list = new ArrayList <> ( ) ;
listOrSingleEl = list ;
list . add ( firstEl ) ;
list . add ( foo ) ;
} else { // Real, multiple-element list
( ( ArrayList < Foo > ) listOrSingleEl ) . add ( foo ) ;
}
}
|
Rõ ràng, việc tối ưu hóa như vậy làm cho source code của bạn khó read hơn và maintain khó hơn. Nhưng bạn nên biết rằng bạn sẽ tiết kiệm rất nhiều bộ nhớ theo cách này, hoặc sẽ loại bỏ được các khoảng tạm dừng dài GC, nó có thể đáng giá.
Và điều này có thể đã khiến bạn nghĩ: làm cách nào để biết collections nàoứng dụng của tôi đang lãng phí bộ nhớ và mức độ lãng phí là bao nhiêu?
Câu trả lời ngắn gọn là: khó để tìm ra mà không cần tool thích hợp. Cố gắng đoán số lượng bộ nhớ được sử dụng hoặc lãng phí bởi các cấu trúc dữ liệu trong một ứng dụng lớn, phức tạp là không khả thi. Và không biết chính xác bộ nhớ đang lãng phí ở chỗ nào, bạn có thể dành nhiều thời gian theo đuổi các mục tiêu sai trong khi ứng dụng của bạn vẫn cứng đầu với OutOfMemoryError.
Vì vậy, bạn cần phải kiểm tra heap memory trong ứng dụng của bạn bằng một tool. Cách tối ưu nhất để phân tích bộ nhớ JVM (được đo bằng lượng thông tin có sẵn so với tác động của công cụ đối với hiệu suất ứng dụng) là lấy một heap dump data và sau đó phân thích. Một heap dump về cơ bản là full snapshot của heap. Nó có thể được thực hiện tại một thời điểm tùy ý bằng cách gọi tiện ích jmap, hoặc JVM có thể được cấu hình để tự động tạo ra nó nếu nó fail với OutOfMemoryError. Nếu bạn Google cho “JVM heap dump”, bạn sẽ thấy ngay một loạt các bài viết giải thích chi tiết cách lấy heap dump.
Một heap dump à một binary file về size của heap của bạn, vì vậy nó chỉ có thể được đọc và phân tích bằng các tool đặc biệt. Có một số tool như vậy có sẵn, cả open source và commercial. Tool open source phổ biến nhất là Eclipse MAT; đó là VisualVM và một số tool ít mạnh mẽ hơn và ít được biết đến hơn. Các tool commercial như JProfiler và YourKit, cũng như một công cụ được xây dựng đặc biệt cho phân tích heap dump được gọi là JXRay.
Không giống như các tool khác, JXRay phân tích một vùng heap ngay lập tức cho số lượng lớn các vấn đề phổ biến như duplicate strings và các đối tượng khác, cũng như các cấu trúc dữ liệu tối ưu. Các vấn đề với collections được mô tả ở trên rơi vào thể loại sau. Tool tạo report với tất cả thông tin được thu thập ở định dạng HTML. Ưu điểm của phương pháp này là bạn có thể xem kết quả phân tích mọi lúc mọi nơi và chia sẻ với người khác một cách dễ dàng. Nó cũng có nghĩa là bạn có thể chạy công cụ trên bất kỳ máy nào, bao gồm các máy lớn và mạnh mẽ.
JXRay tính toán chi phí (bao nhiêu bộ nhớ bạn sẽ tiết kiệm được nếu bạn loại bỏ một vấn đề cụ thể) theo bytes và theo tỷ lệ phần trăm của heap được sử dụng. Nó group các collections của cùng một class có cùng một vấn đề …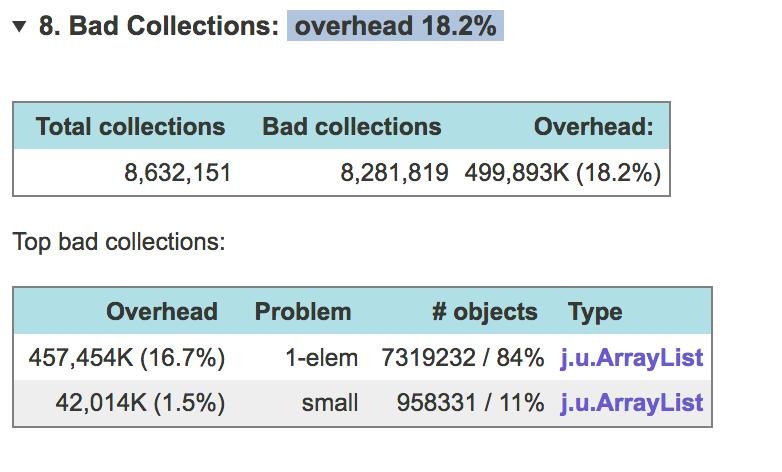
… và sau đó group các collection có vấn đề có thể tiếp cận từ một vài root GC thông qua cùng một chuỗi tham chiếu, như trong ví dụ bên dưới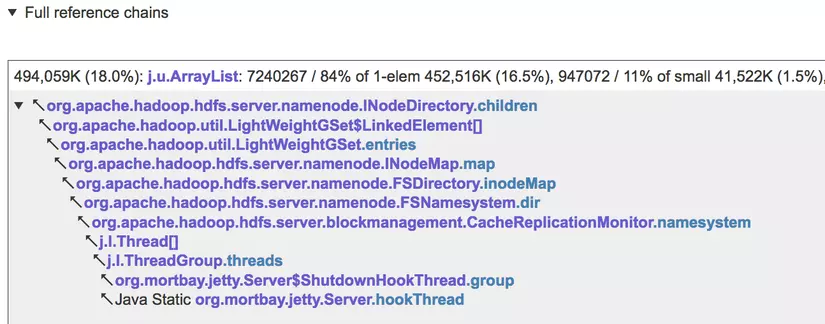
Việc biết chuỗi tham chiếu và / hoặc data field riêng lẻ nào (ví dụ: INodeDirectory.children ở ví dụ trên) trỏ đến collections đang lãng phí bộ nhớ, cho phép bạn nhanh chóng và chính xác xác định phần source code đang gây ra vấn đề và sau đó thực hiện các thay đổi cần thiết.
Tóm lại, Java collections rất dễ để gây lãng phí bộ nhớ. Trong nhiều trường hợp, vấn đề này rất dễ giải quyết, nhưng đôi khi, bạn có thể cần phải thay đổi source code của mình theo những cách không tầm thường để đạt được cải thiện đáng kể. Rất khó để đoán collections nào cần được tối ưu hóa để tạo ra tác động lớn nhất. Để tránh lãng phí thời gian tối ưu hóa các phần source code chưa tốt, bạn cần lấy dump JVM heap ra và phân tích nó bằng một công cụ thích hợp. Vì một tương lai không có OutOfMemoryError error.
Source: https://dzone.com/articles/preventing-your-java-collections-from-wasting-memo
Có thể bạn quan tâm:
- Data hàng trăm ngàn record về địa điểm, bệnh viện, trường học, công viên, sân bay, bến xe buýt,...
- Dữ liệu các hố khoan địa chất công trình
- Dữ liệu về xe hơi sản xuất trong các năm gần đây
- Danh sách và nội dung của tất cả truyện tranh đang thịnh hành. Phục vụ cho việc xây dựng web và app đọc truyện
- Data tất cả các truyện thịnh hành. Phục vụ cho việc xây dựng web và app đọc truyện
DVMS chuyên:
- Tư vấn, xây dựng, chuyển giao công nghệ Blockchain, mạng xã hội,...
- Tư vấn ứng dụng cho smartphone và máy tính bảng, tư vấn ứng dụng vận tải thông minh, thực tế ảo, game mobile,...
- Tư vấn các hệ thống theo mô hình kinh tế chia sẻ như Uber, Grab, ứng dụng giúp việc,...
- Xây dựng các giải pháp quản lý vận tải, quản lý xe công vụ, quản lý xe doanh nghiệp, phần mềm và ứng dụng logistics, kho vận, vé xe điện tử,...
- Tư vấn và xây dựng mạng xã hội, tư vấn giải pháp CNTT cho doanh nghiệp, startup,...
Vì sao chọn DVMS?
- DVMS nắm vững nhiều công nghệ phần mềm, mạng và viễn thông. Như Payment gateway, SMS gateway, GIS, VOIP, iOS, Android, Blackberry, Windows Phone, cloud computing,…
- DVMS có kinh nghiệm triển khai các hệ thống trên các nền tảng điện toán đám mây nổi tiếng như Google, Amazon, Microsoft,…
- DVMS có kinh nghiệm thực tế tư vấn, xây dựng, triển khai, chuyển giao, gia công các giải pháp phần mềm cho khách hàng Việt Nam, USA, Singapore, Germany, France, các tập đoàn của nước ngoài tại Việt Nam,…
Quý khách xem Hồ sơ năng lực của DVMS tại đây >>
Quý khách gửi yêu cầu tư vấn và báo giá tại đây >>








